Tất Tần Tật Các Thông Tin Về Xôi Lạc Tv
Trang chủ Xoilac TV là một trang web xem bóng đá trực tuyến cực kỳ chất lượng tại Việt Nam. Cùng khám phá về trang web uy tín này để hiểu hơn về những thông tin chi tiết
Link xem bóng đá Xoilac cập nhật ngày 20-10-2024

Xôi lạc tv được biết đến là một trang web theo dõi bóng đá trực tuyến đầu tiên tại Việt Nam. Trang web này được ra đời nhằm phục vụ nhu cầu xem bóng đá của những người đam mê với các chuyên gia bóng đá tận tình và các kỹ thuật viên IT có trình độ cao trong việc dựng kênh. Bài viết hôm nay chúng tôi sẽ giúp người đọc tìm hiểu về kênh trực tuyến uy tín này nhé.
Xôi Lạc Tv - Nền tảng thể thao trực tuyến nổi bật 2023
Xoi lac tv là một trang web hay một ứng dụng theo dõi bóng đá trực tuyến dành cho tất cả những người yêu thích bộ môn thể thao này trên màn hình điện thoại nhỏ hoặc có thể xem trực tiếp trên máy tính website. Với sự nỗ lực và phát triển không ngừng nghỉ, xôi lạc tv đã ngày càng cải tiến và mang đến những chức năng độc đáo, mới lạ.

Bên cạnh đó, trang web này còn sở hữu đa dạng các nội dung đặc sắc từ phim ảnh, âm nhạc, truyền hình, giáo dục cho đến những chương trình thể thao hữu ích. Một trong những ưu điểm của kênh trực tuyến này chính là cơ chế hoạt động vô cùng linh hoạt và tối ưu việc sử dụng ngày càng năng suất.
Ngay từ những ngày mới ra mắt, xoi lac tv đã có những mục đích hoàn thành sứ mệnh riêng để trở thành một trang web theo dõi bóng đá đứng hàng đầu Việt Nam. Chính vì thế mà kênh trực tuyến đã đầu tư vô cùng kỹ lưỡng, tốn biết bao tiền bạc, công sức và sự nhiệt huyết đặt trọn vào trong đó để xây dựng tên tuổi của trang web hay ra mắt ứng dụng tiện lợi như ngày hôm nay.
TÍnh đến thời điểm hiện tại, xôi lạc tv đã hoàn thành được những mục tiêu và sứ mệnh của mình để được nhiều người theo dõi biết đến. Và trong tương lai, trang web hữu ích này sẽ hứa hẹn người dùng về sự cố gắng và nỗ lực hơn để xây dựng một kênh bóng đá online uy tín hàng đầu thế giới với chất lượng sản phẩm luôn được đảm bảo.
Ưu Điểm Của Xôi Lạc Tv
Phải công nhận một điều rằng, trang web trực tuyến này sở hữu nhiều ưu điểm vượt trội so với các trang web tương tự được ra mắt trên thị trường. Xôi lạc tv mang đến cho người xem những trải nghiệm tuyệt vời nhất khi thiết kế giao diện cực kỳ thân thiện với những gam màu sắc hài hòa.
Không những thế, nơi đây còn cung cấp đa dạng các nội dung về tin tức được cập nhật mới nhất như các bộ phim hay hot nhất hiện nay, các chương trình ca nhạc, truyền hình, thể thao hay các nội dung giải trí khác. Chính điều này đã giúp người theo dõi có thể tìm kiếm những nội dung, thông tin mà mình yêu thích hay muốn tìm kiếm một cách dễ dàng.
Chưa dừng lại ở đó, xôi lạc tv còn cho phép người dùng được thưởng thức hình ảnh, video ở chất lượng cao và luôn đảm bảo chất lượng rõ nét và âm thanh sinh động, cuốn hút. Vì thế mà khi đến với kênh trực tuyến này, bạn sẽ có cảm giác như đang được tận mắt chứng kiến trực tiếp với những trận đấu hấp dẫn và mang lại những trải nghiệm thực tế hơn.
Tính Năng Hiện Đại Và Sự Phát Triển Của Xôi Lạc Tv
Hầu hết, những người đang trải nghiệm đều đánh giá xoi lac tv là một trang web xem trực tuyến có tính năng hiện đại với các giao diện đơn giản nhưng dễ dàng sử dụng và ngày càng được đổi mới, nâng tầm phát triển hơn.
Tính năng được nâng cấp
Xôi lạc tv không những đáp ứng nhu cầu giải trí mà tại đây còn cung cấp thêm nhiều tính năng nổi bật thường xuyên để nâng cao trải nghiệm cho người dùng. Một trong những tính năng hiện đại mà trang web online này đang sở hữu chính là khả năng xem bóng đá trực tuyến cùng với các chương trình truyền hình luôn đạt chất lượng 4K.
Chính bởi điều này sẽ luôn đảm bảo chất lượng hình ảnh sắc nét mang tính chi tiết cực cao và mang đến những “ luồng gió” mới lạ cho anh em theo dõi. Đặc biệt hơn, nơi đây còn hỗ trợ người dùng về các chức năng ghi chép lại nội dung và cho phép bạn có thể lưu trữ các chương trình thể thao bóng đá hay tin tức mà mình yêu thích để xem lại sau này.
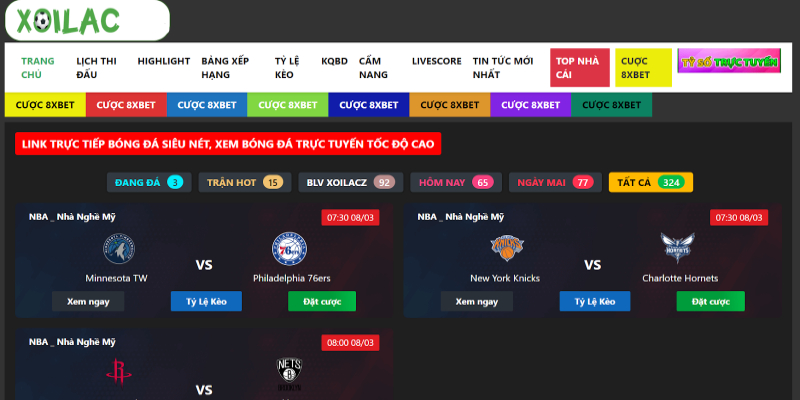
Những tính năng nâng cao và hiện đại này sẽ giúp mọi người theo dõi không bỏ lỡ bất cứ nội dung nào diễn ra tại trang web và luôn có những giây phút tận hưởng và thư giãn theo chính lịch trình của bản thân.
Sự phát triển vượt bậc
Xôi lạc tv là một trong những kênh theo dõi trực tuyến phổ biến ngày càng được nhiều người xem và biết đến. Chính vì thế mà trang web này luôn “ mở đường dẫn lối” để sự phát triển ngày càng được thể hiện rõ hơn và có tiềm năng lớn nhất thị trường. Trong thời gian sắp đến, xoi lac tv sẽ mở rộng thêm nội dung về tin tức cùng với các tính năng hiện đại bắt kịp xu thế để luôn đáp ứng cho mọi nhu cầu của các đối tượng người dùng.
Viết ra mắt các ứng dụng trên các thiết bị và nền tảng mạng xã hội như TV Box hay Smart TV sẽ giúp kênh theo dõi trực tuyến này tiếp cận với nhiều người quan tâm hơn và mở ra những cơ hội phát triển khẳng định vị thế.
Giao diện tại đây luôn được cập nhật thường xuyên nhằm bắt kịp xu hướng của thời đại và tạo cảm giác hứng thú cho mọi người theo dõi. Mặc dù thế, kênh xem trực tuyến chất lượng này vẫn được sắp xếp bố cục các nội dung khoa học, thân thiện giúp cho bạn có thể tìm kiếm các mục thông tin một cách dễ dàng hơn.
Màu sắc trong màn hình giao diện cực kỳ bắt mắt mang đến những trải nghiệm thú vị trong quá trình sử dụng. Hạn chế sự mỏi mắt khi nhìn màn hình quá lâu để sử dụng các dịch vụ hấp dẫn tại nơi này.
Các Chức Năng Nổi Bật Của Xôi Lạc Tv
Nhắc đến xoi lac tv, anh em đều nhắc đến những tính năng cung cấp hoàn toàn miễn phí cho mọi người theo dõi. Không những thế, nơi đây còn sở hữu thêm nhiều chức năng hữu ích khác trong bộ môn bóng đá như là:
- Cập nhật thông tin, tin thức thường xuyên: các sự kiện liên quan đến lĩnh vực bóng bóng đá luôn được update mỗi ngày ở mọi giải đấu trên toàn thế giới. Chưa dừng lại ở đó, tin tức mà trang web trực tuyến cập nhật luôn đầy đủ và đa dạng giúp anh em có thể nắm được những tình hình của bóng đá chi tiết hơn.
- Lịch thi đấu của các giải đấu đều được cập nhật nhanh chóng và đầy đủ giúp người theo dõi có thể nắm bắt được những trận đấu sẽ diễn ra ở một cột mốc cụ thể. Nhờ vậy mà những người quan tâm có thể sắp xếp thời gian để theo dõi trực tiếp các trận đấu mà mình yêu thích.

- Kết quả sẽ được cập nhật sau mỗi trận đấu. Không những thế, xôi lạc tv còn đưa ra các video highlight về những pha thi đấu đi vào lòng người.
- Kênh theo dõi trực tuyến còn đưa ra các tỷ lệ kèo cá cược chính xác nhất cho toàn bộ các trận đấu sẽ được diễn ra trong một thời gian gần nhất. Thông tin trên bảng kèo cá cược sẽ luôn được cập nhật chính xác nhất và hỗ trợ trong việc soi kèo hữu dụng.
- Nơi đây còn sở hữu tính năng xem bóng đá miễn phí và đảm bảo chất lượng trong mọi giải đấu lớn giúp người xem có thể theo dõi các trận đấu mình yêu thích.
Lời Kết
Toàn bộ những thông tin trên đây sẽ giúp người theo dõi biết rõ hơn về trang web xôi lạc tv một cách chi tiết và đầy đủ nhất. Cùng truy cập vào trang web để được nắm bắt những những tin quan trọng mới nhất nhé.



